Azure Data Factory (ADF) is the cloud-based ETL, ELT, and data integration service within the Microsoft Azure ecosystem.
In not-as-technical terms, Azure Data Factory is typically used to move data that may be of different sizes and shapes from multiple sources, either on-premises or in the cloud, to a data store such as a data lake, data warehouse, or database. This can be a component of a robust Modern Data & Analytics platform strategy using Microsoft Azure. There’s a slew of reasons to move this data into a data lake or data warehouse. Still, the primary goal is usually the aggregation and transformation of data into more powerful insights.
If you want a deeper dive into Azure Data Factory, when to use it, and all of its capabilities, I highly recommend you start by reading the introductory post from Microsoft. The rest of this post will assume readers have some familiarity with cloud ecosystems and will primarily focus on Azure Data Factory’s dynamic capabilities and the benefits these capabilities add for cloud and data engineers.
Parameterization in Azure Data Services and Its Benefits
In 2018, Microsoft released Azure Data Factory v2, and with this release, there were many notable changes to ADF. You can read about all of the changes in this release announcement by Microsoft. In this blog, we will primarily focus on exploring the ability to now create parameterized data pipelines within Azure Data Factory.
Parameterization is such a notable addition to ADF because it can save a tremendous amount of time and allow for a much more flexible Extract, Transform, Load (ETL) solution, which will dramatically reduce the cost of solution maintenance and speed up the implementation of new features into existing pipelines. These gains are because parameterization minimizes the amount of hard coding and increases the number of reusable objects and processes in a solution.
To get a general grasp of how parameterization is done and how it can maximize efficiency within an ADF pipeline, let’s take a look at some typical ADF architecture diagrams when using a pipeline without parameterization, and then compare them to a couple of architecture diagrams that increasingly use this added functionality.
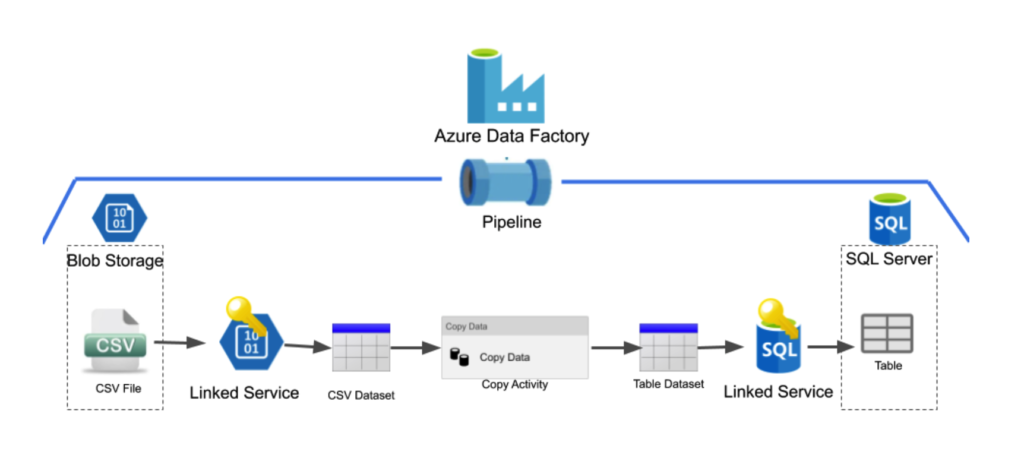
The diagram above is a simple example of an Azure Data Factory pipeline and we will use it throughout the blog for demonstration purposes. In this example, we want to move a single CSV file from blob storage into a table stored in an SQL server database. This activity is done through an Azure Data Factory pipeline. ADF pipelines consist of several parts and typically consist of linked services, datasets and activities. They are:
A Linked Service is used to connect a data store to ADF. It is very similar to a connection string in that it defines the connection information needed for ADF to connect to external resources, such as blob storage or an SQL database.
A dataset is a named view of data that simply points to or references the data you want to use in your activities as inputs and outputs.
Activities in a pipeline define the actions you wish to perform on your data. For this example, we will focus on the copy activity which simply copies the data from one dataset to the other.
To create the example pipeline above a user would need to create all of the following:
- A linked service to allow ADF access to blob storage
- A dataset, which references the target CSV file in blob storage
- A linked service to allow ADF access to the SQL server database
- A dataset, which references the target table in the SQL server database
- A copy activity that will copy the data from the first dataset to the second
Once you have created all of the linked services, datasets and the copy activity, this pipeline will then populate the table in the SQL server database with the data that was in the original CSV file.
This simple pipeline works wonderfully for copying a single CSV file into the SQL table. Now let’s take a look at a diagram where we want to copy over two CSV files into two separate tables in the SQL database.
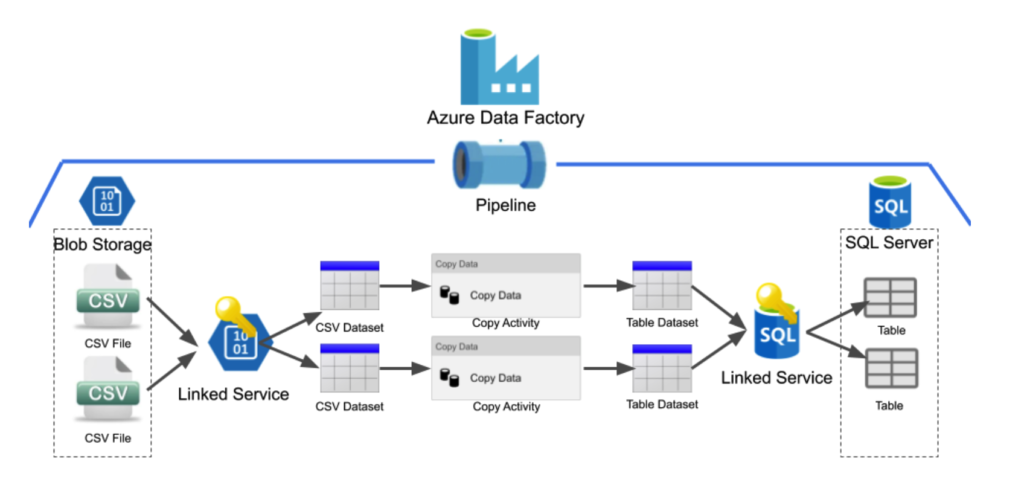
As you can see from the diagram above, adding in steps to copy an additional CSV file into a new table will require the user to create three other objects:
- A dataset to point to the new CSV file
- A dataset to point to the new table
- A copy activity, which will copy the data from the new CSV dataset to the new Table dataset.
* The linked services will not need to be replicated as Azure Data Factory access has already been granted to blob storage and the SQL Server database.
Before parameterization, for every additional file we wish to copy over into our database, we needed to create three other objects. It’s easy to see that if we had a large number of files we needed to transfer, it would require a lot of time to create all of these additional objects in ADF and might be prone to error given the scale of the work. Parameterization can solve these problems.
Below is a diagram of our example pipeline where the dataset objects are utilizing parameterization.
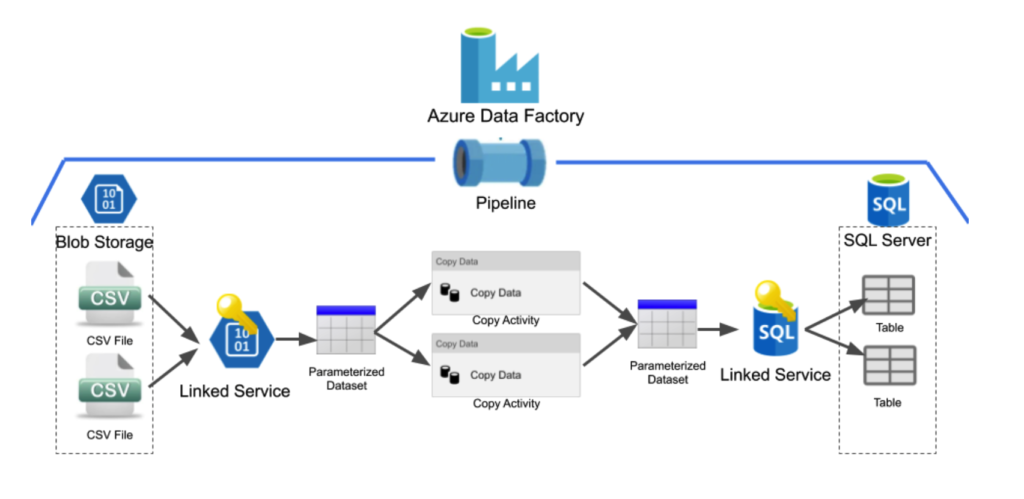
As we can see from the above diagram, parameterizing the datasets eliminates the need to create new dataset objects for every CSV file we wish to copy into a table.
Parameterizing datasets is done through the use of parameters, variables and expressions.
Parameters are input values for operations in ADF. Before execution, each action within ADF needs to have a set of predefined parameters. Additionally, some blocks like pipelines and datasets allow for custom parameters.
Variables are temporary values that are used within pipelines and workflows in ADF to control the execution of the workflow. Variables can be modified through expressions using the Set Variable action during the execution of the workflow.
Expressions are JSON-based formulas, allowing for the modification of variables or any other parameters within a pipeline, action or connection in ADF.
To parameterize the dataset objects, a user creates a parameter for each of the dataset objects upon creation. For our example above, a user would create a parameter for the CSV dataset populated with the file path of a CSV we wish to copy. Alternatively, when creating the Table dataset object, the user would create a parameter that should be populated with the name of the table we wish to populate.
Once these parameters are created for the datasets, a dynamic variable will be passed to the dataset objects through the pipeline to populate them. In the above diagram, the copy activity will pass variables to both the CSV and Table dataset objects at runtime indicating what data they should be referencing. The copy activity is able to pass these variables to the datasets because the user will fill in these parameters each time a copy activity is created.
Adding this capability to the datasets is fantastic and allows us to only create one-third of the additional objects that we would have needed if we wanted to add an additional source file without any parameterization. Even though this solution is better, there are still redundancies in the solution. This solution still requires users to manually create each copy activity for every CSV file they wish to copy into their database. Luckily this can be reduced through another layer of parameterization.
Below is an Azure Data Factory pipeline diagram that ideally uses parameterization and creates the least amount of redundancy possible.
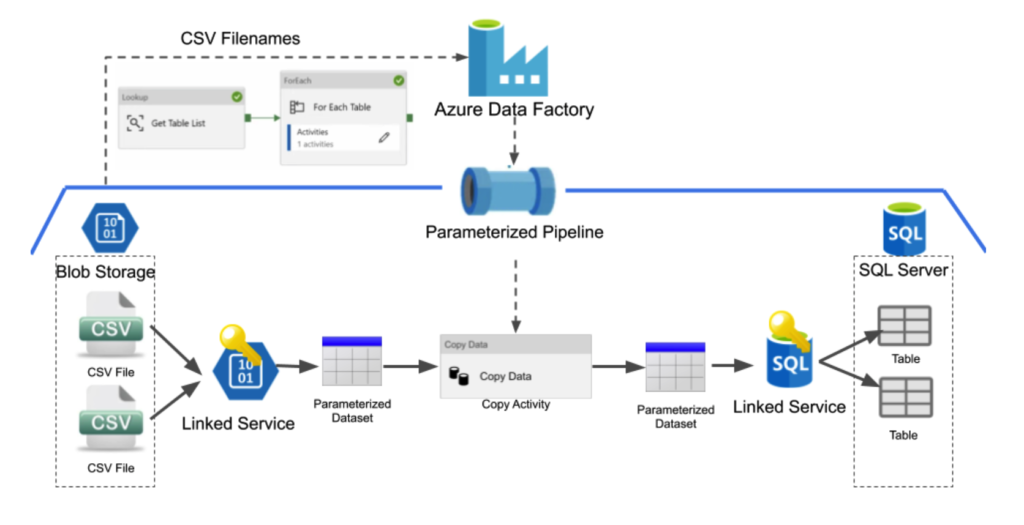
In the above diagram, we can see we no longer need to create additional copy activities for every additional CSV file we wish to copy over into our SQL database because we are now using parameterization in our entire pipeline. The new pipeline is created by adding an additional level of parameterization to the copy activity. The source CSV file and destination table are now parameters that need to be passed into the copy activity, which will then pass these parameters into the dataset objects.
In the above example, this is being done by pulling all of the files stored within blob storage with the Lookup activity. The Lookup activity will retrieve all the content in a data store and in this case create a list of all the files in blob storage. After using the Lookup activity to retrieve all the filenames, we then iterate through all of the file names using the ForEach activity.
The ForEach activity in the Azure Data Factory pipeline allows users to call a new activity for each of the items in the list that it is referring to. In our example, we would be calling the same copy activity we used for all previous pipelines for each of the file names in the blob storage and would pass the file name in as a parameter to the copy activity. This pipeline would then populate the respective tables in the SQL database for each of the files that were in blob storage. This makes this a dynamic solution – one that can adjust and require no additional work if the files in blob storage change and will help reduce the number of errors due to being automated.
Conclusion
As previously stated, parameterization is extremely useful because it allows for a much more flexible ETL solution, which will dramatically reduce the cost of solution maintenance and can save a tremendous amount of time. If you are utilizing Azure Data Factory anytime soon, you should consider the aspects of your solution that you could make dynamic through parameterization.
Some typical scenarios that parameterization allows for, and you should use, are:
- Dynamic input file names coming in from an external service
- Dynamic output table names
- Appending dates to outputs
- Changing connection parameters like database names
- Conditional Programming
- And many more
If you want a more explicit demonstration of how to specifically parameterize and build dynamic data pipelines in Azure Data Factory, I highly recommend watching this video posted by the Microsoft Ignite Youtube Channel, or reading the official Azure Data Factory documentation.
At Productive Edge, we work with leading organizations to transform their businesses and elevate the customer experience. To learn more about how the technology consultants at Productive Edge can help your business, contact us.




